cloud-native application
What is a cloud-native application?
A cloud-native application is a program that is designed for a cloud computing architecture. These applications are run and hosted in the cloud and are designed to capitalize on the inherent characteristics of a cloud computing software delivery model. A native app is software that is developed for use on a specific platform or device.
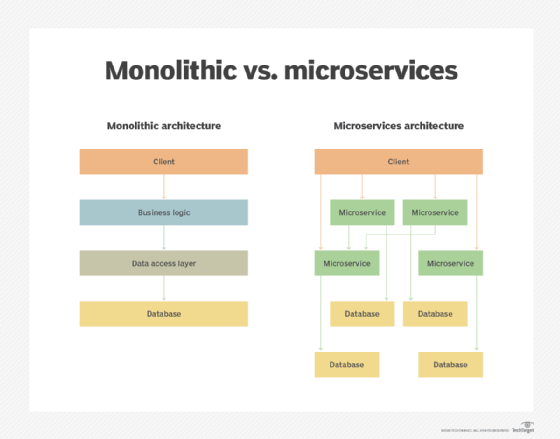
Cloud-native applications use a microservice architecture. This architecture efficiently allocates resources to each service that the application uses, making the application flexible and adaptable to a cloud architecture.
Proponents of DevOps use cloud-native applications for their ability to promote business agility. They are designed, built and delivered differently from traditional cloud-based monolithic applications. Cloud-native applications feature shorter application lifecycles and are highly resilient, manageable and observable.
Basics of cloud-native application architecture
Cloud-native apps take advantage of cloud computing frameworks and their loosely coupled Cloud services. Because not all services are on the same server, cloud-native application developers must create a network between machines using software-based architectures. The services reside on different servers and they run in different locations. This architecture enables applications to scale out horizontally.
At the same time, because the infrastructure that supports a cloud-native app does not run locally, these applications must be designed with redundancy. This allows the application to withstand an equipment failure and remap Internet Protocol (IP) addresses automatically.
Features of a cloud-native application
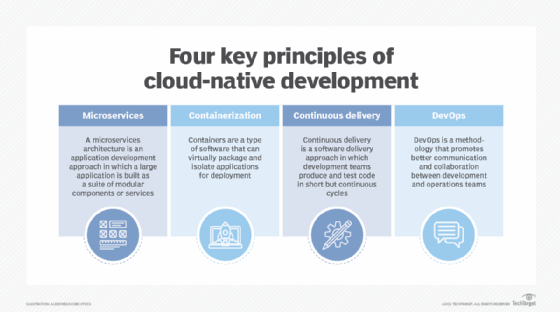
The microservices that are part of the cloud-native app architecture are packaged in containers that connect and communicate via APIs. Orchestration tools are used to manage all of these components.
Here are some of the key capabilities of these applications:
- Microservices-based. Microservices break down an application into a series of independent services, or modules. Each service references its own data and supports a specific business goal. These modules communicate with one another via application program interfaces (APIs).
- Container-based. Containers are a type of software that logically isolates the application enabling it to run independent of physical resources. Containers keep microservices from interfering with one another. They keep applications from consuming all the host's shared resources. They also enable multiple instances of the same service.
- API-based. APIs connect microservices and containers while providing simplified maintenance and security. They enable microservices to communicate, acting as the glue between the loosely coupled services.
- Dynamically orchestrated. Container orchestration tools are used to manage container lifecycles, which can become complex. Container orchestration tools handle resource management, load balancing, scheduling of restarts after an internal failure and provisioning and deploying containers onto server cluster nodes.
Cloud-native vs. cloud-based apps
The terms cloud-native and cloud-based applications are often confused. While they both run on public, private or hybrid cloud infrastructures, they differ in design as follows:
Cloud-based applications
These are designed to use the cloud and cloud platforms Cloud-based applications may use dynamic cloud infrastructure but do not take full advantage of the inherent characteristics of the cloud.
Cloud-native applications
These are designed specifically for the cloud. Cloud-native application development is optimized for the inherent characteristics of the cloud and is adaptable to the cloud's dynamic environment.
Benefits of cloud-native applications
Cloud-native applications are designed to take advantage of the speed and efficiency of the cloud. Some of the benefits from using them include the following:
- Cost-effective. Computing and storage resources can scale out as needed. This eliminates the overprovisioning of hardware and the need for load balancing. Virtual servers can be added easily for testing and cloud-native applications can be up and running fast. Containers can also be used to maximize the number of microservices run on a host, saving time, resources and money.
- Independently scalable. Each microservice is logically isolated and can scale independently. If one microservice is changed to scale, the others will not be affected. Should some components of an application need to update faster than others, a cloud-native architecture accommodates this.
- Portability. Cloud-native applications are vendor neutral and use containers to port microservices between different vendors' infrastructure, helping avoid vendor lock-in.
- Reliable. If a failure occurs in one microservice, there's no effect on adjacent services because these cloud-based applications use containers.
- Easy to manage. Cloud-native applications use automation to deploy app features and updates. Developers can track all microservices and components as they're being updated. Because applications are divided into smaller services, one engineering team can focus on a specific microservice and doesn't have to worry about how it will interact with other microservices.
- Visibility. Because a microservice architecture isolates services, it makes it easier for engineering teams to study applications and learn how they function together.
Best practices for cloud-native application development
Best practices for designing cloud-native applications are based on the DevOps principal of operational excellence. Cloud-native architecture has no unique rules, and businesses will approach development differently based on the business problem they are solving and the software they are using.
All cloud-native application designs should consider how the app will be built, how performance is measured and how teams foster continuous improvement through the app lifecycle. Here are the five parts of design:
- Automate. Automation allows for the consistent provisioning of cloud application environments across multiple cloud vendors. With automation, infrastructure as code (IaC) is used to track changes in a source code repository.
- Monitor. Teams should monitor the development environment, as well as how the application is being used. The environment and the application should make it easy to monitor everything from the supporting infrastructure to the application.
- Document. Many teams have a hand in building cloud-native apps with limited visibility into what other teams are doing. Documentation is important to track changes and see how each team is contributing to the application.
- Make incremental changes. Any changes made to the application or the underlying architecture should be incremental and reversible. This will enable teams to learn from changes and not make permanent mistakes. With IaC, developers can track changes in a source repository.
- Design for failure. Processes should be designed for when things inevitably go wrong in a cloud environment. This means implementing test frameworks to simulate failures and learn from them.
Tools for cloud-native app development
Several software tools are used for each cloud-native application development process. Together, they create a development stack.
Here is the software found in a cloud-native development stack:
Docker. The Docker platform is open source. It creates, deploys and manages virtualized application containers using a common operating system (OS). It isolates resources allowing multiple containers to use the same OS without contention.
Kubernetes. The Kubernetes platform is used to manage and orchestrate Linux containers, determining how and where the containers will run.
Terraform. Designed for implementing IaC, Terraform defines resources as code and applies version control so users can see when and where resources were altered.
GitLab CI/CD. This continuous integration/continuous development (CI/CD) software lets users automate software testing and deployment. GitLab can be used for security analysis, static analysis and unit tests.
Node.js. This JavaScript runtime is useful for creating real-time applications like chat, news feeds and other microservices. For example, Node.js can create virtual servers and define the routes that connect microservices to external APIs.
The future of cloud-native applications
Cloud-native applications have seen increased use in recent years and are predicted to be the future of software development. The Cloud Native Computing Foundation estimated there were at least 6.5 million cloud-native developers in 2020 compared to 4.7 million in 2019.
Cloud-native applications solve some of cloud computing's inherent problems. Nevertheless, migrating to the cloud to improve operational efficiencies has a range of challenges.






