What is PaaS? Platform as a service definition and guide
What is PaaS? Platform as a service definition
Platform as a service (PaaS) is a cloud computing model where a third-party provider delivers hardware and software tools to users over the internet. Usually, these tools are needed for application development. A PaaS provider hosts the hardware and software on its own infrastructure. As a result, PaaS frees developers from having to install in-house hardware and software to develop or run a new application.
PaaS tools tend to be touted as simple to use and convenient. An organization might find the move to PaaS compelling considering potential cost savings over on-premises alternatives.
How does PaaS work?
As mentioned above, PaaS does not replace a company's entire IT infrastructure for software development. It is provided through a cloud service provider's hosted infrastructure. Users most frequently access the offerings through a web browser. PaaS can be delivered through public, private and hybrid clouds to deliver services such as application hosting and Java development.
Other PaaS services include the following:
- development team collaboration;
- application design and development;
- application testing and deployment;
- web service integration;
- information security; and
- database integration.
Users will normally have to pay for PaaS on a per-use basis. However, some providers charge a flat monthly fee for access to the platform and its applications.
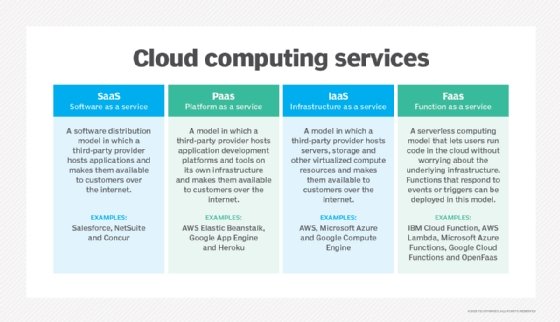
What are the differences between PaaS, IaaS and SaaS?
PaaS is one of three main categories of cloud computing services. The other two main cloud computing categories are infrastructure as a service (IaaS) and software as a service (SaaS):
- With IaaS, a provider supplies the basic compute, storage and networking infrastructure along with the hypervisor -- the virtualization layer. Users must then create virtual instances such as VMs and containers, install OSes, support applications and data, and handle all of the configuration and management associated with those tasks. Some examples of IaaS services are DigitalOcean, AWS, Azure and Google Compute Engine.
- With PaaS, a provider offers more of the application stack than IaaS, adding OSes, middleware -- such as databases -- and other runtimes into the cloud environment. PaaS products include AWS Elastic Beanstalk and Google App Engine.
- With SaaS, a provider offers an entire application stack. Users simply log in and use the application that runs completely on the provider's infrastructure. Typically, SaaS applications are completely accessible via internet web browser. SaaS providers manage the application workload and all underlying IT resources; users only control the data created by the SaaS application. Examples of SaaS include Salesforce, Dropbox and Google Workspace.
PaaS vs. SaaS
The difference between PaaS and SaaS can be murky. Both models provide access to services often based in a cloud, so it's worth drawing the distinction between platforms and software.
A SaaS offering provides access to a finished application or workload, such as an HR or finance application, in exchange for a recurring fee. The SaaS application is hosted on the provider's own remote infrastructure. This eliminates the need for a business to purchase, deploy and maintain that application in-house, enabling the business to reduce its in-house IT footprint.
A PaaS offering typically provides access to an array of related applications or tools intended to help businesses perform complex interrelated tasks; the most common example is software development and testing. PaaS components are also hosted on the provider's own infrastructure, and users can access the platform's components for a recurring fee. PaaS can eliminate an entire tool set from the local data center, further easing the organization's IT burden.
The key difference is that SaaS offers a finished workload, while PaaS offers the tools needed to help a business create and manage its own workload.
PaaS pros and cons
The principal benefit of PaaS is simplicity and convenience for users. The PaaS provider will supply much of the infrastructure and other IT services, which users can access anywhere through a web browser. The ability to pay on a recurring (subscription) or per-use basis enables enterprises to eliminate the capital expenses they traditionally have for on-premises hardware and software. Effectively, PaaS shifts the responsibility for providing, managing and updating key tools from the internal IT team to the outside PaaS provider.
Many PaaS products are geared toward software development. These platforms offer compute and storage infrastructures, as well as text editing, version management, compiling and testing services that help developers create new software quickly and efficiently. A PaaS product can also enable development teams to collaborate and work together, regardless of their physical location.
PaaS architectures keep their underlying infrastructure hidden from developers and other users. As a result, the model is similar to serverless computing and function-as-a-service architectures -- meaning the cloud service provider manages and runs the server, as well as controlling the distribution of resources.

In terms of disadvantages, however, service availability or resilience can be a concern with PaaS. If a provider experiences a service outage or other infrastructure disruption, this can adversely affect customers and result in costly lapses of productivity. However, PaaS providers will normally offer and support relatively high uptimes -- though availability is governed by the provider's service-level agreement (SLA).
Vendor lock-in is another common concern because users cannot easily migrate many of the services and data from one PaaS platform to another competing PaaS platform. Users must evaluate the business risks of service downtime and vendor lock-in when they select a PaaS provider.
Internal changes to a PaaS product are also a potential issue. For example, if a PaaS provider stops supporting a certain programming language, opts to deliver a different set of development tools or even discontinues some or all of the platform's components, the effect on users can be difficult and disruptive. Users must follow the PaaS provider's service roadmap to understand how the provider's plan will affect their environment and capabilities.
Types of PaaS
Various types of PaaS are currently available to developers:
- public PaaS;
- private PaaS;
- hybrid PaaS;
- communications PaaS (CPaaS);
- mobile Paas (mPaaS);
- open PaaS;
- integration platform as a service (iPaaS);
- database as a service (DBaaS); and
- middleware as a service (MWaaS).
Public PaaS. This model is best fit for use in the public cloud. Public PaaS enables the user to control software deployment while the cloud provider manages the delivery of all other major IT components necessary to the hosting of applications, including OSes, databases, servers and storage system networks.
Public PaaS vendors offer middleware that enables developers to set up, configure and control servers and databases without needing to set up the infrastructure. As a result, public PaaS and IaaS run together, with PaaS operating on top of a vendor's IaaS infrastructure while using the public cloud. Unfortunately, this means the client is tied to a single public cloud option that they might not want to use.
Some small and medium-sized businesses have adopted public PaaS, but bigger organizations and enterprises have refused to embrace it due to its close ties to the public cloud. This is primarily a result of the large number of regulations and compliance issues that fall on enterprise application development within the public cloud.
Private PaaS. A private PaaS option aims to deliver the agility of public PaaS while maintaining the security, compliance, benefits and potentially lower costs of the private data center. This model is usually delivered as an appliance or software within the user's firewall, which is frequently maintained in the company's on-premises data center. A private PaaS can be developed on any type of infrastructure and can work within the company's specific private cloud.
Private PaaS enables an organization to better serve developers, improve the use of internal resources and reduce the costly cloud sprawl that many companies face. Furthermore, private PaaS enables developers to deploy and manage their company's applications while also abiding by strict security, privacy and compliance requirements.
Hybrid PaaS. Combining public and private PaaS, hybrid PaaS affords companies the flexibility of infinite capacity provided by a public PaaS with the cost efficiencies and control of owning an internal infrastructure in private PaaS. Hybrid PaaS uses a hybrid cloud.
Communication PaaS. CPaaS is a cloud-based platform that enables developers to add real-time communications to their apps without the need for back-end infrastructure and interfaces. Normally, real-time communications occur in apps that are built specifically for these functions. Examples include Skype, FaceTime, WhatsApp and the traditional phone.
CPaaS provides a complete development framework for the creation of real-time communications features without the necessity of a developer building their own framework, including standards-based application programming interfaces, software tools, prebuilt apps and sample code.
CPaaS providers also help users throughout the development process by providing support and product documentation. Some providers also offer software development kits, as well as libraries that can help build applications on different desktop and mobile platforms. Development teams that choose to use CPaaS can save on infrastructure, human resources and time to market.
Mobile PaaS. MPaaS is the use of a paid integrated development environment for the configuration of mobile apps. In an mPaaS, coding skills are not required. MPaaS is delivered through a web browser and typically supports public cloud, private cloud and on-premises storage. The service is usually leased with pricing per month, varying according to the number of included devices and supported features.
MPaaS usually provides an object-oriented drag-and-drop interface that enables users to simplify the development of HTML5 or native apps through direct access to features such as the device's GPS, sensors, cameras and microphone. It often supports various mobile OSes.
Companies often use mPaaS for the creation of applications that will provide both internal and customer-facing uses. This implementation can promote a BYOD environment and productivity apps without the requirement of mobile app developers or extra IT support.
Open PaaS. A free, open source, business-oriented collaboration platform that is attractive on all devices, Open PaaS provides useful web apps including calendar, contacts and mail applications. Open PaaS was designed to enable users to quickly deploy new applications. It has the goal of developing a PaaS technology that is committed to enterprise collaborative applications, specifically those deployed on hybrid clouds.
Integration platform as a service. IPaaS is a broad umbrella for services used to integrate disparate workloads and applications that might not otherwise communicate or interoperate natively. An iPaaS platform seeks to offer and support those disparate integrations and ease the organization's challenges in getting different workloads to work together across the enterprise.
Database as a service. DBaaS is a provider-hosted database workload that is offered as a service. DBaaS can involve all database types, such as NoSQL, MySQL and PostgreSQL database applications. A DBaaS model is generally provided through a recurring subscription and includes everything that users need to operate the database, which can be accessed by local and other cloud-based workloads using APIs.
Middleware as a service. MWaaS provides a suite of integrations needed to connect front-end client requests to back-end processing or storage functions, enabling organizations to connect complex and disparate applications using APIs. MWaaS is similar in principle to iPaaS in that the focus is on connectivity and integrations. In some cases, MWaaS can include iPaaS capabilities as a subset of MWaaS functions, which can also involve B2B integration, mobile application integration and IoT integration.
What's the difference between PaaS and iPaaS?
Although PaaS and iPaaS have similar-sounding names, they are supported by different technologies, and the two cloud services have different purposes.
IPaaS automation tools connect software applications deployed in different environments and are often used to integrate on-premises data and applications with those stored in a cloud. An iPaaS platform is more closely aligned with -- and treated as -- middleware and can be included as part of MWaaS offerings.
PaaS, on the other hand, provides cloud infrastructure, as well as application development tools delivered over the internet.
PaaS uses
PaaS tools are frequently used in the development of mobile applications. However, many developers and companies also use PaaS to build cross-platform apps because it provides a fast, flexible and dynamic tool that has the ability to create an application that can be operated on almost any device. At its core, PaaS provides a faster and easier way for businesses to build and run applications.
Another use of PaaS is in DevOps tools. PaaS can provide application lifecycle management features, as well as specific features to fit a company's product development methodologies. The model also enables DevOps teams to insert cloud-based continuous integration tools that add updates without producing downtime. Furthermore, companies that follow the Waterfall model can deploy an update using the same console they employ for everyday management.
PaaS can also be used to reduce an application's time to market by automating or completely eliminating housekeeping and maintenance tasks. Additionally, PaaS can decrease infrastructure management by helping to reduce the burden of managing scalable infrastructure. PaaS removes the complexities of load balancing, scaling and distributing new dependent services. Instead of the developers controlling these tasks, the PaaS providers take responsibility.
With the support that PaaS provides for newer programming languages and technologies, developers can use the model to introduce new channels of technical growth, such as with container technology and serverless functions. This is especially relevant to industries where technological change is a slow process -- for example, banking or manufacturing. PaaS enables these organizations to adapt to the newest offerings without completely changing their business processes.
PaaS examples: Products and vendors
There are many examples of PaaS vendors and products that supply the tools and services needed to build enterprise applications and integrations in the cloud. The following are some of the leading providers and platforms:
- Google Cloud
- Microsoft Azure
- AWS
- IBM Cloud
- Red Hat OpenShift
- VMware (Pivotal) Cloud Foundry
- Oracle Cloud Platform (OCP)
- Heroku container-based PaaS
- Mendix aPaaS
- Engine Yard Cloud PaaS
- OpenStack
- Apache CloudStack
- Wasabi Cloud Storage
Google App Engine supports distributed web applications using Java, Python, PHP and Go. Red Hat OpenShift is a PaaS offering for creating open source applications using a wide variety of languages, databases and components. The Heroku PaaS offers Unix-style container computing instances that run processes in isolated environments while supporting languages such as Ruby, Python, Java, Scala, Clojure and Node.js.
Microsoft Azure supports application development in .NET, Node.js, PHP, Python, Java and Ruby, and enables developers to use software developer kits and Azure DevOps to create and deploy applications.
AWS Elastic Beanstalk enables users to create, deploy and scale web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go and Docker on common servers, such as Apache, Nginx, Passenger and IIS.
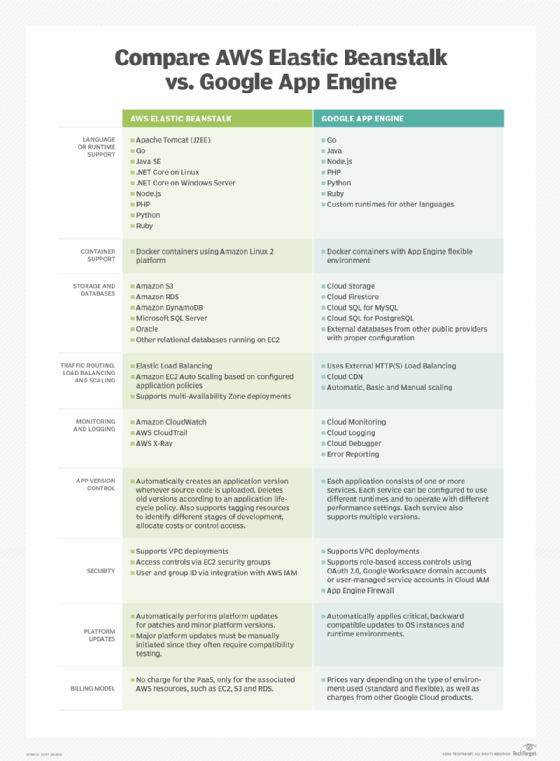
Although many PaaS providers offer similar services, each provider has unique nuances and limitations. Users should test prospective providers to ensure their services meet any business or technical requirements, such as supported languages and service availability. As examples, Wasabi offers cloud-based object storage as a PaaS, while open platforms such as OpenStack and Apache CloudStack enable organizations to build their own private PaaS resources.
What's included in a platform as a service?
Specific PaaS capabilities can vary between different vendors and products. However, the core suite of PaaS features typically includes infrastructure, development tools, middleware, OSes, database management tools and analytics:
- Infrastructure. PaaS includes everything that IaaS includes. This means PaaS providers will manage the servers, storage, data centers and networking resources. This can also include the UI or portal that users employ to interact with the PaaS infrastructure and services.
- Application design, testing and development tools. PaaS provides customers with everything they need to build and manage applications. These tools can be accessed over the internet through a browser, regardless of physical location. The specific software development tools often include but are not limited to a debugger, source code editor and a compiler.
- Middleware. PaaS also usually includes middleware, the software that bridges the gap between OSes and end-user applications. Therefore, PaaS subscribers do not have to commit their in-house developers and resources to building middleware.
- OSes. OSes for applications to run on, as well as for the developers to build the application from, are provided by the PaaS vendor.
- Databases. PaaS providers often will maintain databases, as well as providing the customer organization's developers with database management tools.
- Monitoring and management tools. PaaS providers will frequently include business intelligence services, such as monitoring and analytics, to help business users understand how the PaaS is being used and help explain per-use costs and utilization characteristics.
Who oversees PaaS in an organization?
Control of PaaS is sometimes a matter of perspective and is typically a shared responsibility between providers and users.

The PaaS provider actually owns and operates the PaaS platform. The provider owns and runs the underlying infrastructure. They are responsible for building, deploying, managing and maintaining the software applications and services within the PaaS offering. The provider must ensure that the PaaS is running properly and adheres to promised SLAs. When trouble strikes, the provider must troubleshoot and remediate any problems.
For all practical purposes, PaaS is a third-party resource -- a business partner -- upon which the user's business depends. In the case of a private PaaS where an organization will build its own platform, the provider and the user, or customer, are the same.
But PaaS is a major paradigm shift for countless organizations seeking to improve their productivity and shed local infrastructure. The decision to use PaaS, the goals and expectations of PaaS adoption, the choice of specific PaaS, the ongoing monitoring of PaaS use and the ultimate determination of PaaS value or success are all made by business leaders.
Considering the importance of PaaS adoption, PaaS oversight and management is rarely the role of a single individual within the business. It typically depends on a collaborative effort across the organization's IT department:
- The CIO/CTO can drive a PaaS initiative, directing staff to examine and evaluate PaaS as a supplement or alternative to locally managed tool sets.
- Software architects and engineers can recognize and help select a specific PaaS as a meaningful engine for workload development, modernization and integration.
- Developers work with the PaaS product and are often key staff involved in PaaS evaluation and selection.
- IT administrators might be involved with PaaS management, taking responsibility for PaaS setup, configuration, security and monitoring from the user/customer perspective.
- Other business leaders, such as legal compliance officers, can also be involved in PaaS decisions to ensure that PaaS use adheres to business continuance and regulatory requirements of the organization.
Best practices for evaluating and buying PaaS
The move to PaaS can be intimidating. Success with PaaS depends on a keen understanding of business needs, clear identification of PaaS offerings and capabilities and a significant amount of trust. Several practices can help organizations evaluate and migrate to PaaS:
- Understand the need. What is it exactly that a PaaS model needs to do for the business, and how would adopting a suitable PaaS benefit the organization better than traditional local tool sets? For example, the goal might be to improve and streamline Java software development or facilitate complex integrations between new and legacy applications. Business leaders and decision-makers must know what they're looking for before they're able to find it.
- Shop around. There are many PaaS providers and offerings. The scope, features, functionality and performance of each PaaS product can vary dramatically. For example, CPaaS probably would not do when MWaaS is needed. Try some different PaaS offerings and see what works best for the tasks at hand. Shortlist several potential offerings and test them in proof-of-principle projects. The investment of time and effort in such PaaS evaluations can build confidence and experience and prevent buyer's regret later.
- Understand the provider. Take a hard look at the PaaS provider. Adopting PaaS is basically taking on a business partner. Talk to the provider to understand their staffing, business history and model, leadership team, service support and PaaS roadmap. Will the provider and its PaaS be around in two years, five years or longer? What does the PaaS product lifecycle look like?
- Understand the fine print. Consider the costs, billing scheme and support mechanisms. The service costs should be readily understandable and billed in a way that is aligned to the business. In addition, look for an SLA and study it closely: Your business might depend on the PaaS, and the SLA is the provider's only commitment to you as a customer in matters such as uptime, availability and dispute settlement.
- Consider the risks. There is always risk in PaaS adoption. The provider might go out of business. Key features might be deprecated and removed in the future. Promised features of the roadmap might never be implemented. What happens to your workloads if the PaaS experiences service disruptions or becomes unavailable, and how can the business respond to such problems? PaaS carries some amount of lock-in, and it can be difficult -- even impossible -- to migrate to an alternative PaaS.
Modern PaaS vs. traditional PaaS
The fundamental purpose of most PaaS offerings is to simplify and streamline development tasks, but modern PaaS can go far beyond a straightforward assortment of useful tools to create a suite of tightly integrated and complementary applications that focuses on development capabilities, efficiencies orchestration and automation.
As an example, the VMware Tanzu Application Platform is expected to provide a suite of highly integrated Kubernetes-based application deployment and infrastructure management tools. This should enable VMware's cloud-native IT automation products to integrate with the Kubernetes container orchestration platform. It will offer a comprehensive workflow for developers to build apps quickly and test on Kubernetes.
Another mark of a maturing PaaS industry is the rise of outside integrations and support. PaaS offerings such as VMware Tanzu Application Platform should also support other pipeline tools and Kubernetes versions, such as Jenkins and cloud-hosted Kubernetes services. In addition, the offerings should support a greater range of programming languages, such as Python, JavaScript, Go and .NET.
Future of the PaaS market and business model
PaaS has emerged as a cost-effective and capable cloud platform for developing, running and managing applications -- and the PaaS market is expected to gain popularity and grow through 2027. As an example, IDC predicted that the cloud and PaaS market should see a compound annual growth rate of 28.8 percent in 2021 through 2025.
Such expectations are based on the need for businesses to accelerate application time to market, reduce complexity, shed local infrastructure, build collaboration -- especially for remote and geographically distributed teams -- and streamline application management tasks.
PaaS expansion and growth are also being driven by cloud migration and cloud-first or cloud-native application development efforts in concert with other emerging cloud technologies, such as IoT.
The role of iPaaS is also expected to make considerable gains by 2027 as businesses of all sizes seek to modernize, connect and share data between disparate software applications and deliver unified tools across the business and their customer base.






