
freshidea - Fotolia
4 DIY cloud projects to make your business more cloud-friendly
Show your business there's value in doing more in the cloud. Even in a work-from-home world, you can start small with projects that will be catalysts for broader adoption.

If you and your coworkers are working from home, it might not feel like the best time to tackle new projects, especially ones intended to move your organization toward an ideal, "cloudy" version of itself.
However, even now, you can find ways to set your company up for cloud adoption. You can do it by creating in-production examples that your company can later apply across its IT footprint.
Explore these four DIY cloud project ideas and learn how to convince your company to implement these projects on a broader scale.
Set up infrastructure as code
A fully cloud-enabled organization could commit all its infrastructure definitions in versioned, machine-readable files and then re-create that infrastructure by running a simple command. If your infrastructure definitions exist as code, you'll never have knowledge gaps in how to set up critical systems. You'll also have fewer outages and errors related to running your systems.
It can feel daunting to take the first step toward infrastructure as code, especially if your organization has a sizable operations team that manually sets up infrastructure. Yet, infrastructure-as-code offerings have come a long way over the past decade and it's now extremely simple to use tools like AWS CloudFormation or Hashicorp's Terraform.
Start your infrastructure-as-code cloud project by identifying infrastructure your team "owns." If you're on a software development team, it might be your development, staging or QA environment. If you're on an operations team, then it might be something operations owns internally, such as a VM or container that runs automated jobs or one that you're regularly asked to allocate. If you're on another team, it could be the VMs or containers that run your central ticketing or CRM applications.
A typical configuration file for a VM or container, with all its security roles and permissions, is less than 100 lines. If you have a choice between a VM and container -- i.e., it's currently a VM but no one cares if you move it to a container -- you'll likely want to choose a container, because the Dockerfile itself is a form of infrastructure as code. That way, you can specify all the software that needs to be installed on the virtual hardware you have allocated.
Build a data lake
Data lakes are phenomenal resources for driving organizational agility. A data lake is a storage repository that holds data exports from different systems and services. This data can be stored in native layouts and common formats, queried together and even integrated with third-party SaaS tools.
With a data lake, you can centralize reporting to look at multiple systems at once. You can also build services that need data sourced from multiple systems and build easier system integrations without having to build your own APIs.
To start out simple, make your first data lake iteration by taking one system's data and exporting it regularly to a cloud object store that can be queried by a big data querying system. Each of the major cloud providers offers tools to build data lakes.
It's usually not a substantial load to export data on a regular basis from existing systems to a data lake or to build out a first report from a data lake. Ideally, your first report should address a significant pain point -- one that puts unwanted strain on existing systems.
Improve your ETLs
Many organizations struggle to transfer data from one system to another in their back-office footprint. This process is often called Extract, Transform, Load (ETL), but it can have other names and techniques. For example, this is frequently implemented instead as Extract, Load, Transform (ELT). This can involve moving data from multiple systems to a data lake or just from one database to another. Like in the data lake case, the major cloud providers offer their own managed services -- AWS Glue, Cloud Dataproc and Azure Data Factory.
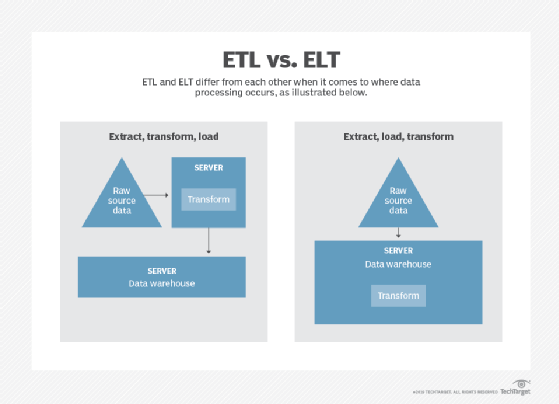
For the purposes of a DIY cloud project, a managed service that is cloud agnostic, such as Fivetran or Stitch, would be the best candidate. These services are substantially better than the ones offered by the cloud providers. They identify schemas and their changes, and they regularly copy data from one system or service to a data lake. These services automatically handle the configuration, change management or operationalization of these tasks.
They also support more data sources, such as third-party services like Zendesk, Salesforce and Stripe, without you having to do anything more than provide an API key.
In my experience, most people dramatically improve their ETL quality and stability in a few hours with a managed data transport service.
Move cron jobs to FaaS
Function-as-a-service (FaaS) offerings, also known as serverless compute platforms, can be good cloud DIY projects. The major cloud providers offer services like AWS Lambda, Google Cloud Functions and Azure Functions, with which a developer can write code and the cloud provider will run it in response to specific events that happen.
For example, you could schedule the code to run every hour of the day or run on each new file that is uploaded via SFTP. FaaS dramatically reduces the operations support required to set up and ensure these jobs are regularly running. It can also make jobs run a lot faster, by separately running these functions in parallel instead of having jobs back up in a queue.
Some great cron job use cases to start out with on FaaS include:
- backups;
- log file analysis;
- automatically making thumbnails of images;
- automatically processing videos;
- automatically downloading or uploading files to/from SFTP sites; and
- automatically sending internal emails.
Office diplomacy to bring the project home
Once you've selected a cloud project that can be accomplished quickly, plan how to explain it to the rest of the organization.
Frame it in the smallest possible scope and focus on the specific problem it will solve. Make it about a solution to that specific problem. Your goal should be to get this project live, and the best way to do so is to make it as innocuous and narrowly relevant as possible.
Many IT professionals would love to see their organization expand its cloud adoption, but they're hampered by the need to coordinate with other teams and departments. Projects that should be simple and small often spiral into an almost Kafkaesque sequence of required approvals and crusty anti-cloud skeptics.
But you don't need mass coordination and approval for every project that proves the value of cloud. It is possible to have these types of projects implemented -- initially -- by one or two people that become the catalysts to move toward a more efficient, reliable, repeatable and easier-to-understand technical infrastructure.







