
Fotolia
A beginner's guide to cloud-native application development
Cloud-native applications have become ubiquitous in IT environments. Learn what it takes to create cloud-native apps and which development tools are available.

Not all organizations define cloud-native applications the same way. At its core, cloud-native means that developers design, develop and deliver a specific application with the scalability and ephemeral nature of the cloud in mind.
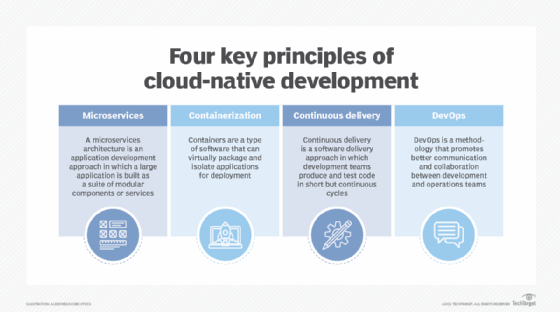
Microservices and containers are often associated with cloud-native application development because apps created in the cloud tend to follow modern development practices. In contrast to the traditional Waterfall software development lifecycle, cloud-native applications are developed with a more agile methodology. Changes are frequently released into a production environment through automated delivery pipelines, and infrastructure is managed at the code level.
The ephemeral nature of the cloud demands automated development workflows that can deploy and redeploy as needed. Developers must design cloud-native applications with infrastructure ambiguity in mind.
This has led developers to rely on various tools to provide a reliable platform to run their applications on without having to worry about the underlying resources. Influenced by Docker, developers have used the microservices model which enables highly focused, yet loosely coupled services that scale easily.
There are a few factors of the Twelve-Factor App methodology -- a go-to reference for application developers -- that are foundational to cloud-native application development, which are detailed below.

Build, release, run
The build, release, run approach separates each stage of the development and deployment of cloud-native applications.
- Build. An application's codebase goes through the build state, where it's transformed from raw source code into an executable bundle known as the build.
- Release. The build is then combined with any necessary configuration values that are required to run in the targeted environment -- this is known as the release.
- Run. The release executable is run in the targeted performance environment.
This well-defined workflow is often coupled with a deployment and continuous integration tool, like Jenkins or Capistrano, which can run automated tests, roll back to previous builds and more. If something goes wrong, developers can rerun a prebuilt release in an environment or on a different infrastructure without having to redeploy the entire application.
Processes
In cloud computing, decoupled, stateless processes are far more scalable and manageable than stateful ones. While it can seem counterintuitive to develop a stateless process, it emphasizes the reliance on stateful backing services that enable the stateless processes to scale up and down -- or reboot altogether -- with minimal risk to the application's quality.
While you can execute cloud-native processes in any number of ways, some targeted environments, such as Heroku, offer their own runtimes that are based on configuration values provided by the developer. This is commonly done through the use of a containerization technology, such as Docker and Kubernetes. Containers are an excellent way to encapsulate the single process required to run a given application and encourage the use of stateless applications.
Concurrency
Cloud-native applications are hard-wired to be horizontally scalable because they isolate services into individual stateless processes that can handle specific workloads concurrently. Processes are efficiently scalable when they're stateless and unaware of the other independent processes.
concurrency is a great example of why many cloud-native applications lean toward service-oriented architectures. Monolithic applications can only scale so far vertically. Each component can scale more effectively to handle the load when a developer breaks a monolithic app into multiple targeted processes. A host of tools are available to automate the management and scaling of these processes, including Kubernetes and other proprietary services from cloud service providers.
Disposability
Several cloud providers offer more volatile infrastructures at a reduced cost. This promotes cheaper scalability but comes with the risk of the sudden disposal of processes. While this isn't always the case, cloud-native applications designed for disposability emphasize the importance of self-healing applications.
Plan for unexpected failures to enable smoother shutdown procedures and store any stateful data outside of the isolation of the process. However, it is easier to design a self-repairing system using orchestration tools, like Kubernetes, and robust queuing back ends, such as Beanstalkd or RabbitMQ.






