Compare NoSQL database types in the cloud
NoSQL systems are increasingly common in the cloud. Read about the different types of NoSQL databases that are available from major cloud providers and other vendors.
The emergence of globally scalable online services for social networks, streaming content, news distribution, retail and other business uses significantly changed the requirements for application infrastructure and software architectures. One of the most substantial transformations came in the way IT systems store, organize and provide access to data.
Mainstream relational database management system (RDBMS) software, such as Oracle Database and SQL Server, is a poor match for web applications that require distributed, scale-out cluster infrastructure. NoSQL databases are a better fit for loosely coupled systems in which application data and executable code are spread across multiple machines and perhaps data centers. They can also handle data sets that don't fit well within the rigid schema of SQL-based relational databases, which work best with structured data.
With their origins often rooted in the open source community, NoSQL vendors have built various types of databases to target different kinds of data and use cases. Oracle, Microsoft and other RDBMS vendors also eventually developed NoSQL databases. Now, with the overall market shifting toward cloud databases, cloud-native development has taken hold: NoSQL databases are widely available in the cloud both for self-managed IaaS deployments and vendor-managed database as a service (DBaaS) ones.
Pros and cons of NoSQL databases
Because web applications and services were the primary drivers behind NoSQL development, the various types of NoSQL databases have some advantages over RDBMSes. These include the following:
- the ability to handle a variety of data types;
- higher performance and lower latency in certain applications;
- ideal for unstructured and semistructured data, such as text, images, audio and video;
- horizontal scaling capabilities for large workloads and data volumes;
- well suited for time series or other streaming data, such as event logs and IoT data; and
- access to a wide variety of open source or low-cost implementations that are cheaper to procure and operate than a sophisticated RDBMS.
However, these benefits come at a cost in other ways. For example, relational database systems ensure more immediate data consistency and reliability through the ACID model: atomicity, consistency, isolation and durability. NoSQL databases usually follow the BASE model: basic availability, soft state and eventual consistency, although some now support ACID transactions.
Also, these nonrelational databases often lack built-in mechanisms to check data integrity; in such cases, it must be done in external code. Lastly, while many NoSQL databases include some SQL capabilities, they typically don't support complex SQL operations, such as compound select statements or table joins.
NoSQL database categories
The right way to think about NoSQL isn't as a certain type of database, but rather as an umbrella category with several variants as follows:
- Key-value store. This database organizes data sets as a sequence of records that include a unique key paired with a data value. It uses hash tables to store the keys with pointers to the associated values, which can be a single entry or a complex data object with multiple elements. A key-value store is like a dictionary, in that each key is like a word and the value represents its meaning.
- In-memory cache. This is a type of key-value store designed to fit entirely within system memory. Doing so accelerates performance and potentially reduces cost by removing the need to scale an entire database just to handle a certain application feature or scenario.
- Document database. It stores data objects in key-value pairs, but it puts them in document-like structures that can also embed metadata about the contents. Sometimes called a document store, the database typically encodes documents in JSON, XML, YAML and other text formats or binary variants, such as BSON.
- Search database. A search database is a specialized document store in which the document indices can be sharded and distributed across multiple nodes to provide massive scalability to accelerate the retrieval of particular entries.
- Wide-column store. This technology organizes data by columns rather than rows. As its name indicates, a wide-column store can contain tables with many columns, enabling it to handle very large data sets. Columns are grouped into families of related data that's accessed together.
- Graph database. This type of database does away with the common row-column structure in favor of using a graph-like structure to store data sets as a collection of nodes and highlight their relationships to each other.
- Time series database. A TSDB, as it's known for short, collects data that's generated on an ongoing basis and stores it in successive order, commonly with time stamps. Examples include stock market, sensor and IT network data. A time series database can be used to track such data sets and analyze how they change over time.
Key-value stores, document databases, wide-column stores and graph databases are the four major categories of NoSQL databases. In addition, vendors increasingly are turning their products into multimodel databases that support more than one of those categories through different modules.
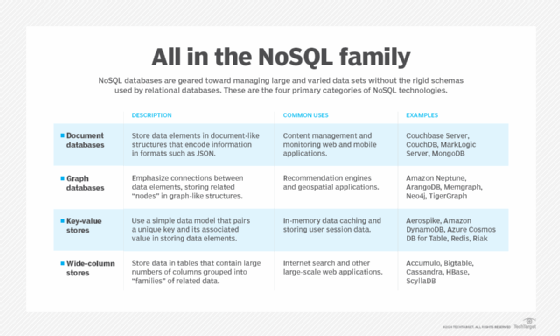
NoSQL database comparison
As public cloud infrastructure became a popular option for running web and mobile applications and other IT workloads, cloud platform market leaders AWS, Microsoft and Google Cloud all built a variety of NoSQL database products and services to suit different data types and use cases. While the details of their product offerings vary, the technologies available from them for each type of NoSQL database are listed in the table below.
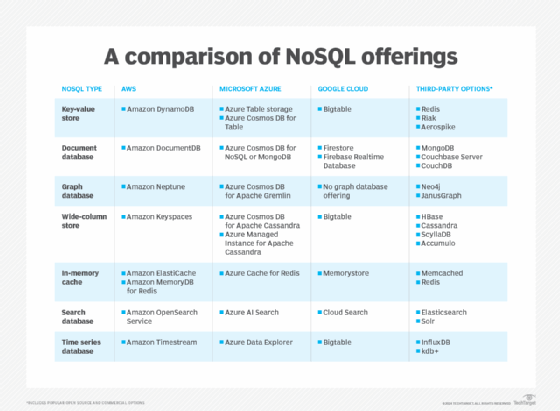
As the comparison table indicates, there are also many other open source and commercial offerings available in the cloud for each NoSQL database type. For DBaaS environments, users can choose between the top cloud platform providers -- the three in the table plus Oracle -- and other NoSQL database vendors that host their software on one or more of those platforms. Each third-party option has its own features and strengths that could make it the best NoSQL in the cloud alternative.
Another big decision on running a NoSQL database in the cloud is the deployment model: privately managed IaaS versus a fully managed database service. The choice hinges on whether an organization prefers a self-managed and highly configurable and controlled database system or a managed DBaaS platform that removes upfront capital expenses and ongoing infrastructure management overhead.
Editor's note: This article, originally written by Kurt Marko in 2019, has been updated by TechTarget industry editor Craig Stedman. Kurt was a longtime TechTarget contributor who passed away in January 2022. He was an experienced IT analyst and consultant, a role in which he applied his broad and deep knowledge of enterprise IT architectures. You can explore all the articles he authored for TechTarget on his contributor page.






