Instill cloud change management best practices
Automation is essential to change management in the cloud. Discover the best practices that ensure your IT team is in sync and productive when handling change.

Change management can be more complex in the cloud than it is on premises. Enterprises oversee a larger number of services when they adopt cloud environments -- a challenge that is exacerbated by the ease and speed with which developers can deploy and update applications, across different regions.
But cloud change management isn't a lost cause. With appropriate planning, organizations can institute processes that automate how they use those services, and incorporate iterative deployment models with technologies like infrastructure as code. Organizations also must go beyond technical aspects of change management and think about the coordination of their staff to ensure everyone's on the same page.
Go beyond IT
In the data center, IT administrators use change management to control the consumption and operations of IT resources. They typically take a prescribed approach through service management frameworks, such as ITIL. There is often a change advisory board, which reviews requests and their potential implications, and might come up with ways to streamline or optimize them.
In the cloud, the biggest difference with change requests is speed, according to Edward Majors, principal at Deloitte Consulting. Cloud users can schedule and deploy releases to production exponentially quicker than they could in the data center.
This article is part of
What is cloud management? Definition, benefits and guide
"Because the change in progression is so quick, change management is no longer just an IT operation," Majors said.
To succeed with cloud change management, organizations must maintain communication across the affected groups, so employees understand the expectations, benefits and effects of releases.
Plan for more
With flexible, on-demand IT resources, cloud users can deploy distributed, flexibly scaled workloads, such as microservices.
The number of services dramatically increases in the cloud when using this model, said Josh Quint, senior director of cloud solutions at ServerCentral Turing Group, a cloud consultancy. As a result, a developer or IT engineer may have to go to multiple places – sometimes even multiple providers -- to make a change instead of working through a single management console. Plus, those changes likely need to take place simultaneously, making manual reconfiguration or provisioning impractical.
Approach change as part of the standard build, integration and deployment process for these services, and it will instill consistency even as releases deploy with increasing frequency. A controlled CI/CD pipeline for code creation, delivery and deployment also standardizes the points of communication between teams. By building a CI/CD pipeline with parameters around each step, the cloud team documents the right way to execute any and all changes to cloud-hosted applications.
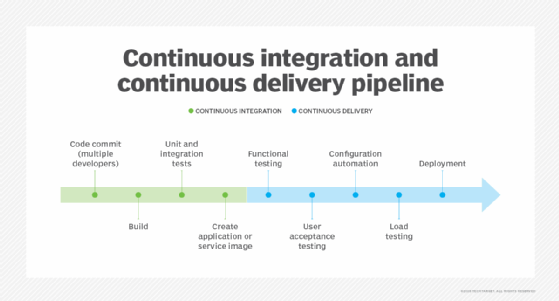
This standardized CI/CD process manages each change in the cloud without gated reviews, as was common in on-premises deployments. It also enables cloud teams to introduce automation to change management. Popular CI/CD tools such as AWS CodePipeline, Jenkins and Azure DevOps can automate how code moves through each phase of a release, including tests and vetting before deployment. These steps generate information about the change, which the team should capture as documentation for the release.
"The unrealized benefit of providing detailed documentation and structure around core processes is the true value automation delivers," Quint said. As a result, change requests become significantly easier to review and implement, because there is a clear path for them and a clear recognition of who should -- and should not -- be involved.
Iterate with stakeholder input
When IT teams move from the still-common Waterfall development approach to an iterative one with small releases through a CI/CD pipeline, they should focus on feedback from stakeholders.
IT teams can take multiple passes at new deployments in order to address feedback from various stakeholders simultaneously, explained Sean Kendall, director of customer experience at TetraVX, an IT consultancy.
Some of the important questions to address as part of this iterative process include:
- Can the users access the software?
- Is appropriate high availability and failover in place?
- How close are we to the cloud provider's data centers, and does it impact latency in a meaningful way?
An agile approach to reviewing and adjusting software based on feedback is more important than any particular tool, Kendall said.
Use infrastructure as code
Change management can be easier if enterprises are diligent about setting up infrastructure as code, said Simon Margolis, director of cloud platform at SADA, a cloud consultancy. The IT resources and hosting aspects of a given change are automated, which makes it easier to track, reproduce and manipulate these infrastructure configurations. Developers can also spin up a duplicate environment quickly from the infrastructure code for testing prior to launch, which is not always practical on premises due to costs.
Margolis recommends HashiCorp Terraform for infrastructure as code. It works on many public clouds and is familiar to many IT engineers and developers. There are also cloud-native options specific to a given platform, such as AWS CloudFormation or Google Cloud Deployment Manager.
Coordinating people
It's also important to plan and track changes, using a work management tool like Asana, Trello or Basecamp Teams need to collaborate, viewing real-time progress and updates, as all the stakeholders keep on top of the cloud changes. "Find a tool that checks all the basic boxes, and ensure it's being used by the whole team," Margolis said.
Flow charts can also help keep everyone on the same page. The visual representation of the cloud change and its deployment process can help spark conversations with engineers about potential issues.
Plan for failure
Organizations also have to approach any cloud environment with the mindset that there will be failures, said Rob Hernandez, CTO of Nebulaworks, a cloud consultancy. This doesn't necessarily require a hybrid or multi-cloud approach. Cloud users can often achieve resilience by spanning availability zones with their deployment and designing instances to failover and reconfigure themselves automatically.
Machine roles that span availability zones should be the default way of operating, Hernandez said. It doesn't require much more work than single-zone configurations, and it provides a significant advantage when something goes wrong with the cloud provider.
Major cloud vendors offer the option for instances to fail, redeploy and resume work without human intervention. For example, this can be achieved on AWS with Auto Scaling groups, which ensures the number of instances in a group is constant, even if there is a failure in an availability zone.






