iconimage - Fotolia
The pros and cons of adding edge computing to a cloud architecture
Edge computing won't make sense for every IoT device or workload. Follow these edge computing examples to know where and when you should use it as part of your cloud architecture.

Edge computing is growing in popularity due to its performance, security and cost benefits over traditional cloud architectures, but it's not always the best fit for distributed workloads.
Edge computing refers to architectures that process data at or near devices that generate and consume data, such as end-user PCs, mobile phones or IoT sensors. This differs from conventional cloud computing, which relies on central servers to receive data, process it and send it back to client devices. Edge computing can reduce network latency, lower the exposure of data to the network and, in some cases, reduces costs by offloading processing to end users' devices.
Due to its appealing advantages, cloud architects might want to push as many workloads as they can to the edge. But before they do, they should consider each application's structure, performance requirements and security considerations, among other factors.
The two types of edge computing architecture
When weighing whether an edge computing model is the right fit, the first question to ask is which type of architecture is available. There are two main types:
- Device-edge computing, in which data is processed directly on client devices.
- Cloud-edge computing, in which data is processed on edge hardware that is geographically closer to client devices than centralized cloud data centers.
The device-edge model works well if the client devices are capable of handling that processing burden in a uniform way. Standard PCs or laptops are equipped to handle this, but low-power IoT sensors may lack the compute and storage resources necessary to process data efficiently.
Also, it can be difficult to use a device-edge model if you're relying on many different types of edge devices and operating systems, all of which can have different capabilities and configurations.
With the cloud-edge model, end-user devices aren't a major factor in shaping your architecture. If you use a cloud edge computing architecture the types of devices that your end-users are using are not important, because you're not offloading data storage or processing from the central cloud to those devices. Instead, you're offloading to servers that run at the edge of the cloud. Those servers would usually be located in a data center that is closer to your end-users than the central cloud.
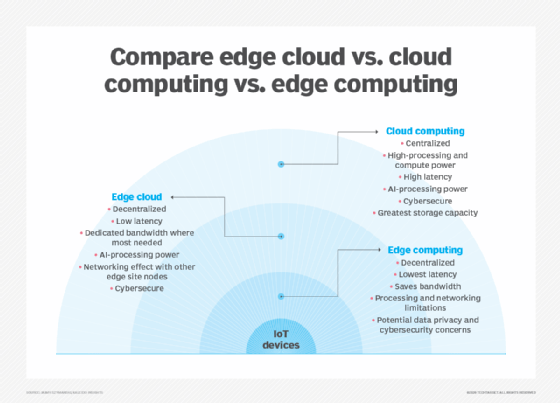
Edge computing limitations
Before you decide to move a workload to the edge, evaluate if it makes sense to support these edge models. These limitations could push you back to a traditional cloud architecture.
Security on the edge
Edge computing reduces some security risks by minimizing the time data spends in transit, but it also introduces more complex security challenges.
For example, if you store or process data on end-user devices you don't control, it's difficult to guarantee those devices are free from vulnerabilities that could be exploited by attackers. And even if you use a cloud-edge model where you retain control over the edge infrastructure, having more infrastructure to manage increases your attack surface.
It's typically easier to secure data in transit over a network -- where it can be encrypted -- than it is to secure data that is being processed. For that reason, the security drawbacks of edge computing may outweigh the advantages.
This makes edge computing less than ideal for workloads with high security specifications. A standard cloud computing model, with its centralized servers, could be less risky if you're dealing with sensitive data or have special compliance requirements.
Latency requirements
Edge computing improves application performance and responsiveness because the data doesn't have to make the round trip to and from cloud data centers to get processed. This is a key advantage for workloads that require truly instantaneous communication streams. Cloud providers continue to add more data center locations, but their massive facilities are often in remote locations far from large population centers.
Most workloads have lower latency standards. Compared to a traditional cloud architecture, an edge network might only improve network responsiveness by a few milliseconds. For standard applications, the delays that come with conventional architectures are acceptable.
Make sure the latency improvements are truly worth the tradeoffs, especially once you factor in the added cost and management burden.
Data volume
Consider how much data your workloads will process, and whether your edge infrastructure can process it efficiently. If you have a workload that generates large data volumes, you'll need an expansive infrastructure to analyze and store that data. It is likely to be cheaper and, from a management perspective, easier to move the data to a public cloud data center.
On the other hand, workloads tend to be good candidates for edge computing if they're largely stateless and don't involve large volumes of data.
Edge computing examples
To illustrate the trade-offs listed above, here are some examples of when edge computing is and isn't a good fit.
Good examples of edge computing include:
- Autonomous vehicles. Self-driving cars collect large amounts of data and need to make decisions in real time for the safety of passengers and others on or near the road. Latency issues could cause millisecond delays in vehicle response times -- a scenario that could have profound impacts.
- Smart thermostats. These devices generate relatively little data. In addition, some of the data they collect, such as the times of day people come home and adjust the heat, may have privacy implications. Keeping the data at the edge is practical and can help mitigate security concerns.
- Traffic lights. A traffic light has three characteristics that make it a good candidate for edge computing: The need to react to changes in real time; relatively low data output; and occasional losses of internet connectivity.
And here are some examples of where edge computing doesn't work too well:
- Conventional applications. It's hard to think of a conventional application that requires the performance or responsiveness of edge infrastructure. It might shave some milliseconds off the time it takes an app to load or respond to requests, but that improvement is rarely worth the cost.
- Video camera systems. Videos generate lots of data. Processing and storing that data at the edge isn't practical because it would require a large and specialized infrastructure. It would be much cheaper and simpler to store the data in a centralized cloud facility.
- Smart lighting systems. Systems that allow you to control lighting in a home or office over the internet don't generate a lot of data. But light bulbs -- even smart ones -- tend to have minimal processing capacity. Lighting systems also don't have ultra-low latency requirements -- if it takes a second or two for your lights to turn on, it is probably not a big deal. You could build edge infrastructure for managing these systems, but it's not worth the cost in most scenarios.





