
yblaz - Fotolia
A better way to query DynamoDB data with SQL
Not everything is a one-click solution. Review two ways to query DynamoDB with SQL, as well as what these methods reveal about AWS' future as the top cloud provider.

Amazon DynamoDB is a fully managed NoSQL database service with numerous practical applications and wide adoption. However, its native methods for querying don't include SQL, even though SQL is sometimes the best way to build reports, especially with tools like Looker and Tableau that rely on the programming language.
DynamoDB has many attractive features. For example, it can automatically scale to handle trillions of calls in a 24-hour period. It can be used as a key-value store or a document database, and it can handle complex access patterns much faster than a typical relational database.
There is support for running SQL to query DynamoDB via PartiQL, but it doesn't meet all users' SQL needs. PartiQL is more of an easier way to query DynamoDB for people who know SQL than it is a way to bring the power of SQL querying to DynamoDB.
In this article, we'll walk through two different methods of making DynamoDB data searchable with SQL:
- A process that stays entirely within the Amazon ecosystem, following AWS' advice and documentation; and
- A process that uses Fivetran, an extract, transform, load (ETL) service, and Google BigQuery.
In doing so, we'll illustrate some of the challenges of integrating DynamoDB with SQL and discuss whether the third-party alternative is the better choice. We'll also evaluate whether these native difficulties on AWS hint at a larger problem for the cloud giant.
Querying DynamoDB with SQL: The Amazon way
The only way to effectively and efficiently query DynamoDB data in AWS is to export it to a system that handles a full SQL dialect and can query the data in a way that is not painfully slow. The two best options for the destination system are:
- Amazon Redshift, which has its own storage mechanism for data. It's the default recommendation and the cheapest option.
- Amazon Athena, which requires you to put files into Amazon S3 to query against.
The Redshift option, illustrated in a blog post here, is not dramatically easier or better than the Athena option. The simplest way to send data to Redshift is to use the COPY command, but Redshift doesn't support complex data types that are common in DynamoDB. The most flexible way to get data from DynamoDB to Redshift is to send it through S3, which means what's detailed in the previously mentioned blog post is just part of the process to get it to Redshift.
Like many processes in AWS, there are multiple ways to send data from DynamoDB to S3, such as using Amazon Data Pipeline, Amazon Elastic MapReduce or the DynamoDB Export to S3 feature. For the purposes of this article, we will use the Export to S3 feature within DynamoDB because it is the simplest option.
Below is the table we will export. It has more than 35,000 items and is more than 4 GB in size. The table has some map and list data types, in addition to more traditional string, number and Boolean type columns.
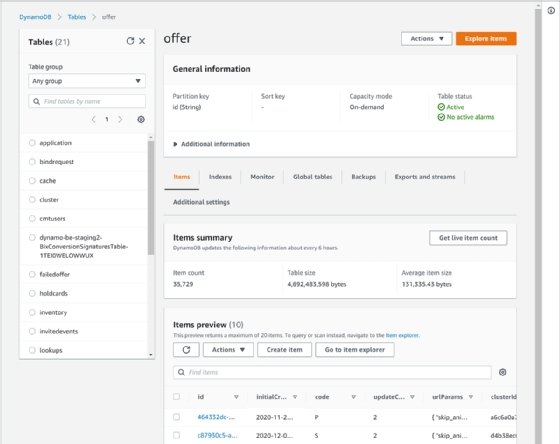
Export from DynamoDB to S3
To start, you might need to opt into the new DynamoDB console -- which is listed as new as of publication -- by choosing the "Try the new preview console" on the left side of the older console. After you choose a table within the preview DynamoDB console, select the tab called "Exports and streams."
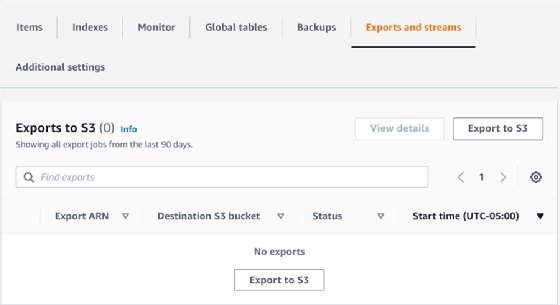
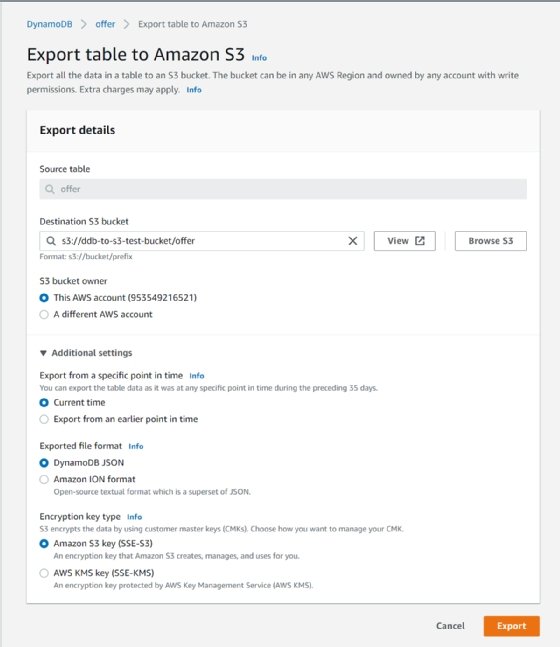
After you choose that, you'll have the choice to "Export to S3" and then you can configure your export by defining the destination S3 bucket. For this walkthrough, the defaults below are fine.
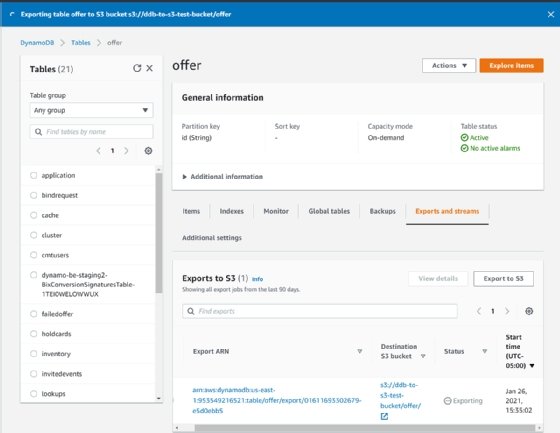
After you click "Export," the process will start, and you can monitor it within the DynamoDB console. In this example, the export took approximately seven minutes.
The next step is to query the data in Athena. First, you need to enable Athena to recognize the data. Athena's documentation focuses on how you can manually define the schema for your JSON files. AWS does offer a service, called AWS Glue, designed to auto-discover the schema of your export, but it doesn't do this very well for Athena. In this case, we'll need to manually define the schema.
Use AWS Glue
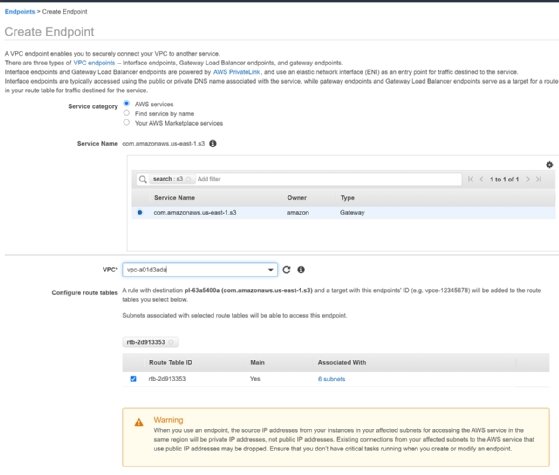
Unfortunately, in order to use AWS Glue, you must have an S3 virtual private cloud (VPC) endpoint set up, even if you don't use an Amazon VPC for anything else. In the VPC service, click "Endpoints." Use the configuration steps shown below to create and add a new endpoint.
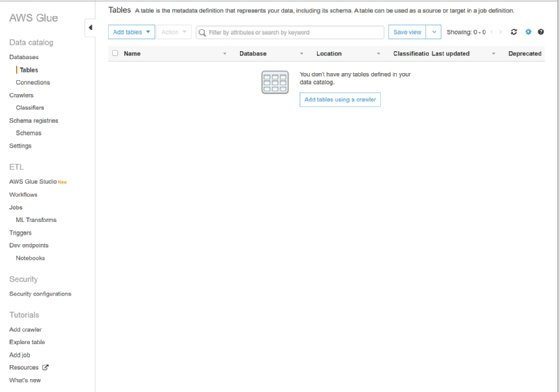
Now we can go to the AWS Glue service, which gives the option to add tables using a crawler.
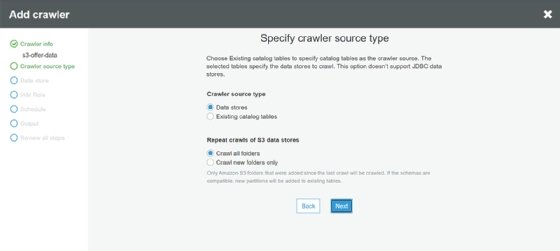
Then, walk through the Glue workflow. Use defaults and select the folder that the data was placed in.
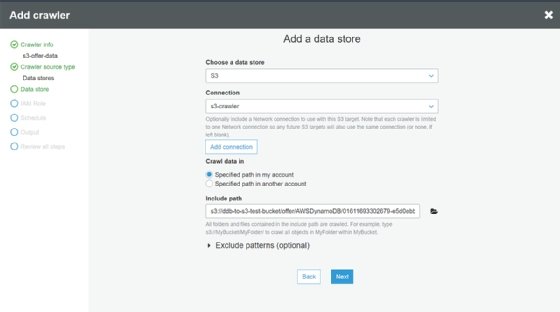
Next, add a new network connection that uses the VPC we set up in S3. Choose the folder in S3 that corresponds to the specific export we previously created.
Glue needs an AWS Identity and Access Management (IAM) role to access the S3 bucket. The service walks through how to create one.
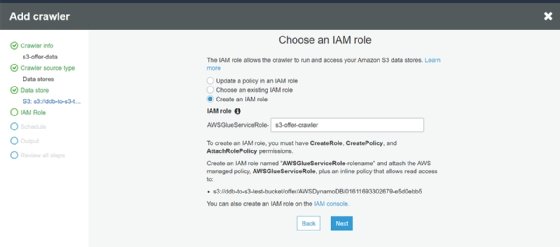
We will make this crawler run on demand, since it just looks at this specific export.
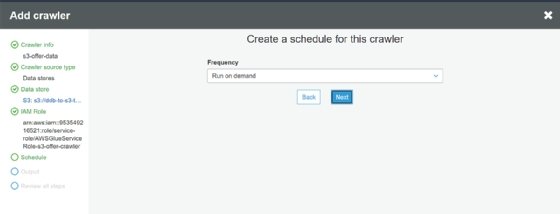
We need to create a database for Athena to see and ask Glue to group compatible schemas together so it aggregates into a single table, which is what we exported.
Finally, we are ready to save the crawler.
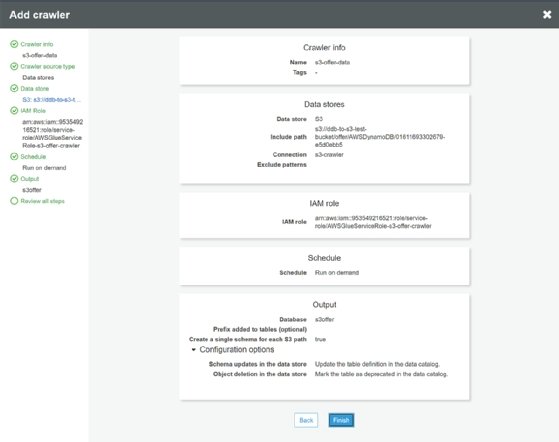
And we can now run it.
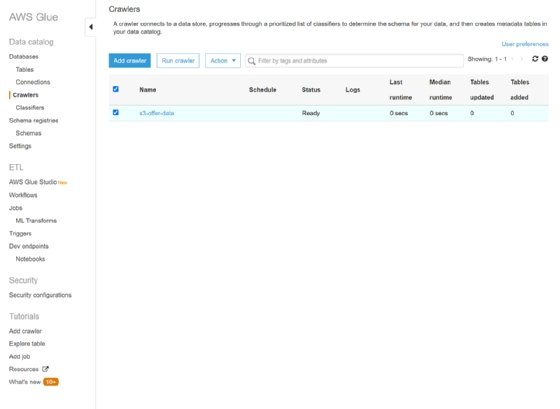
After six minutes, it's completed. Then we jump over to the Athena service and see an error message that says we need to set up an S3 query location, which isn't something we had been told we needed to do beforehand.
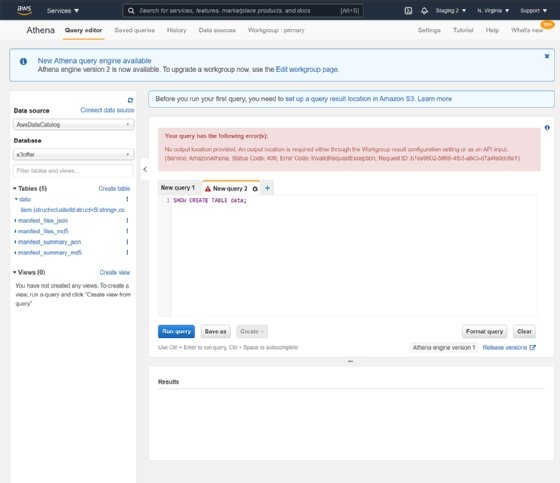
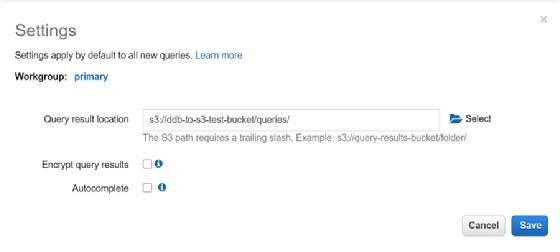
So, we create a place to store queries to address the error message. Then we can attempt to query the data that Glue identified. However, we hit another error because the data in the table was too complex for Glue to identify properly.
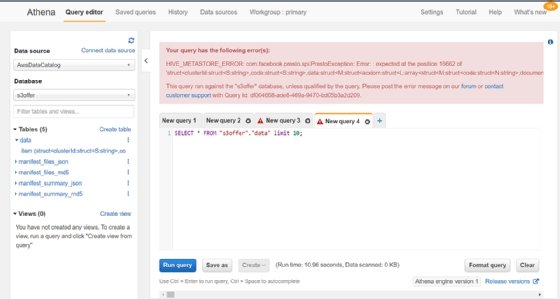
Glue builds a structure that is too complex for Athena to read.
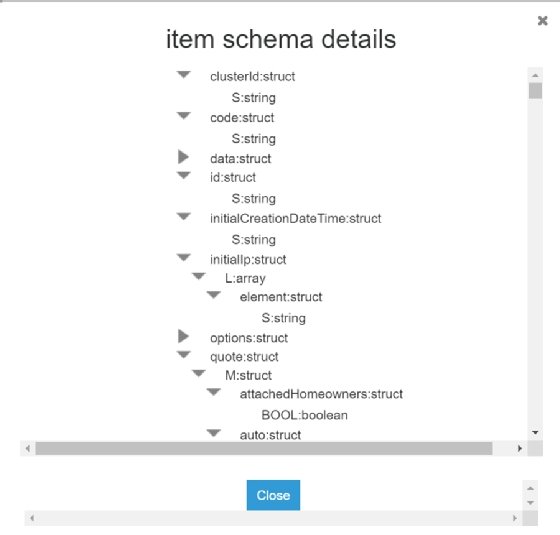
Manually define a schema
If AWS Glue won't identify your schema properly, manually define it. Here is a simple definition of a few top-level fields in the DynamoDB table.
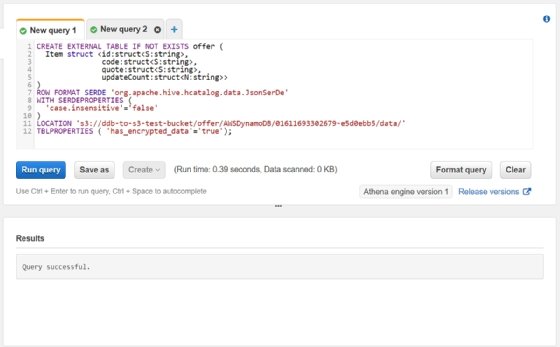
And now we can query it.
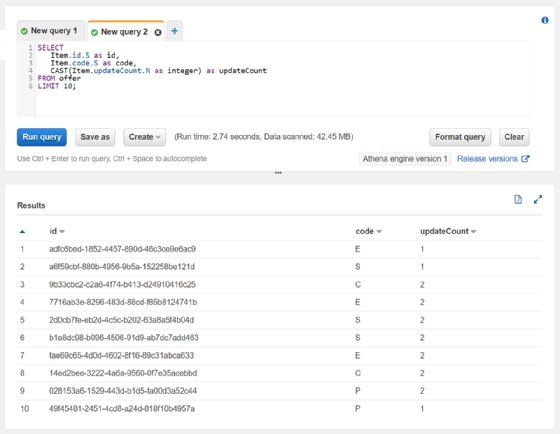
While we can query the data here, it's not ideal. Every record lives under a top-level item, which means that you must define the entire record as a complex type. Records can't be stored as simple types, which is certainly possible in this scenario; it's also the standard for what you'd expect to see in a database. For example, you can't just define some top-level fields as Strings or Integers, because the top-level item is actually a Map.
Also, it's not possible to grab a Map or List as JSON and just expand it or pull data from it as necessary. If you want to reach into it, you must fully define the entire structure so every field you request is a scalar. You also have to deal with casting non-strings every time you want to use them.
Additionally, the export is a point-in-time export, which means it doesn't automatically export each time. If you add any fields anywhere within DynamoDB records, you'll have to redefine the whole "CREATE EXTERNAL TABLE" call.
Querying DynamoDB with SQL: Fivetran and BigQuery
An entirely different approach to this problem is to use a dedicated service that shuttles data from one data store to another, and use a data-querying service that is similar to Athena but more comprehensive.
Fivetran is a fully managed ETL service that copies data regularly -- as frequently as every 15 minutes -- from one place to another. To use Fivetran, you must first connect a destination data store. For the purpose of this example, we will use BigQuery, one of the oldest and most popular cloud-based "big data" databases. However, you can connect Fivetran to other databases, such as Snowflake or even Redshift.
For BigQuery -- assuming you turned on BigQuery access in Google Cloud and have a Google Cloud project -- you just add a Fivetran user to your Google Cloud project and give that user access to BigQuery.
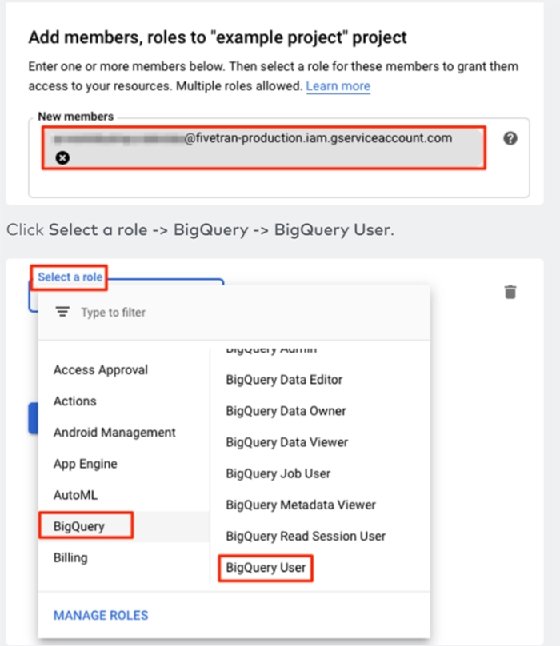
Move data from DynamoDB to BigQuery with Fivetran
To connect Fivetran to DynamoDB, walk through their wizard and give Fivetran access to read the DynamoDB tables you plan to copy outside of DynamoDB. First, create an IAM policy in AWS for Fivetran using a custom ID that Fivetran allocated to your Fivetran account.
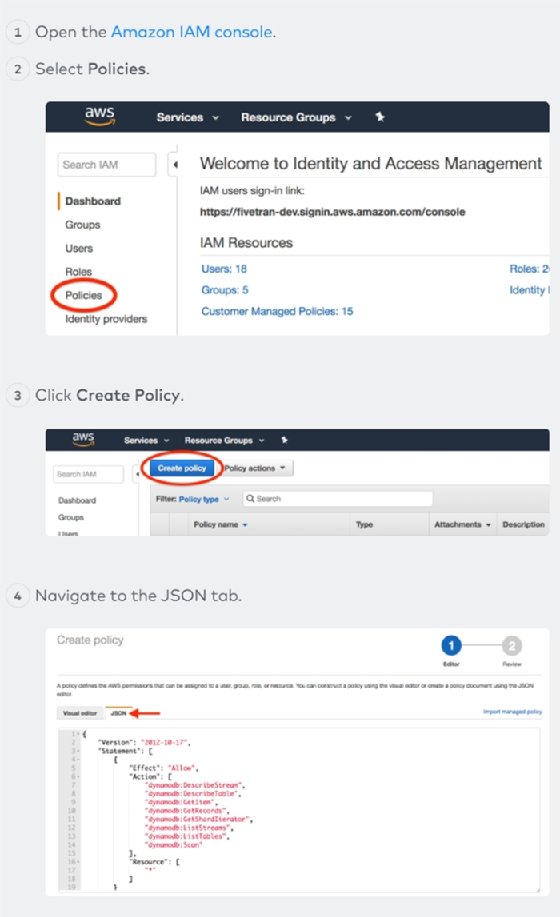
Next, you must create an IAM role that has that policy attached and make it available to Fivetran.
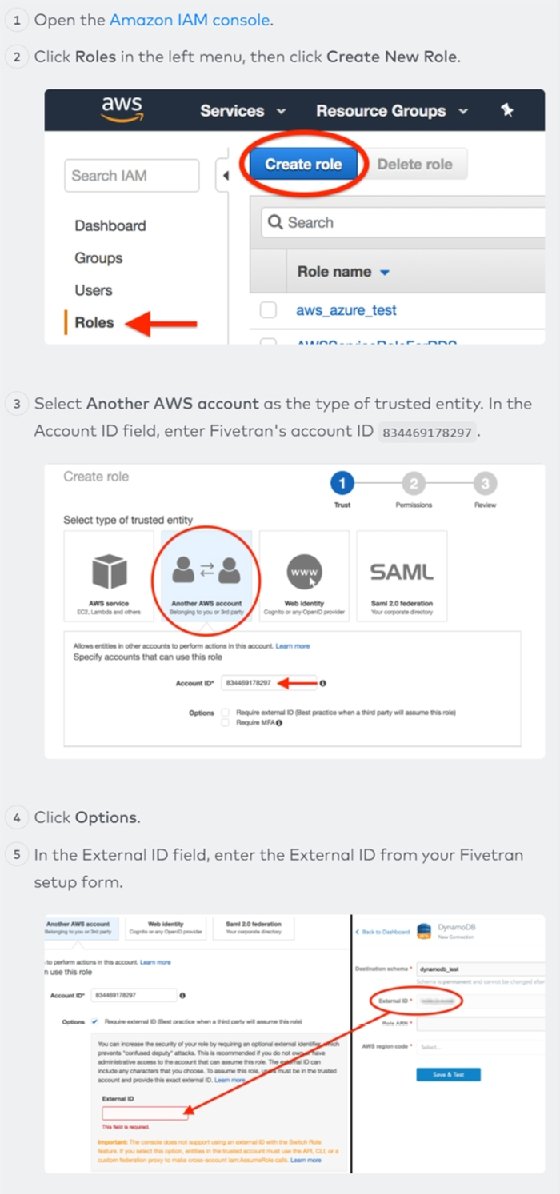
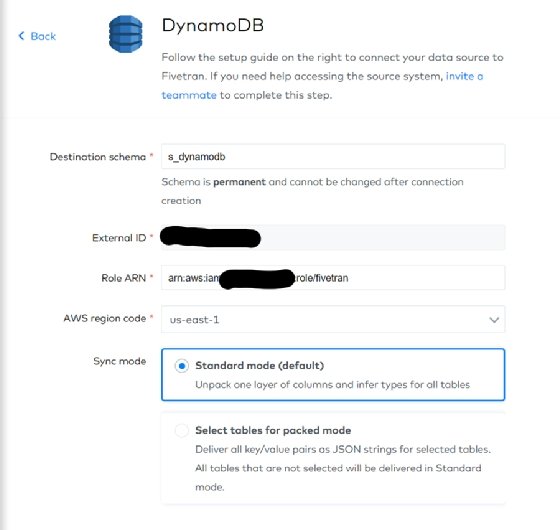
Then, you add a DynamoDB connector in Fivetran by filling the Amazon Resource Name for the role.
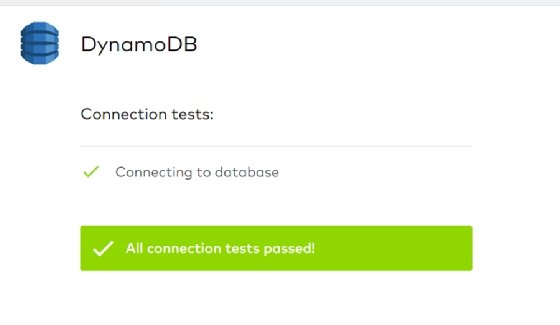
Once you've done this, Fivetran tests the connection.
Then you tell Fivetran to synchronize the tables. In this example, the initial synchronization took 34 minutes.
Querying data in BigQuery
After the initial synchronization, BigQuery shows all the top-level fields automatically pulled in and defined.
You can also arbitrarily extract fields that are deeper within the document structure using BigQuery's JSON functions.
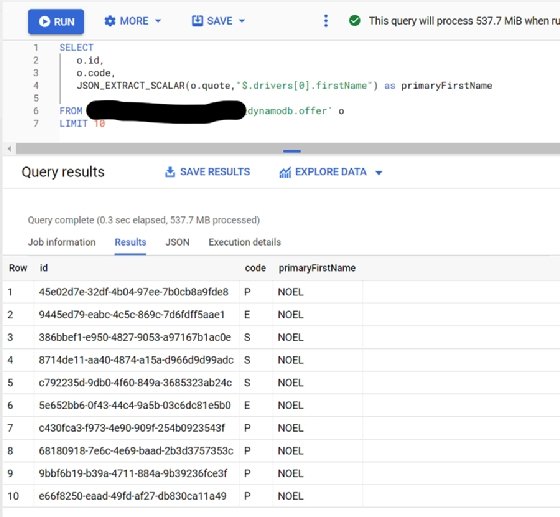
Fivetran also automatically updates the table structure in BigQuery as changes are made within DynamoDB. Fivetran ensures that BigQuery has everything that is within DynamoDB, every 15 minutes.
Drawbacks
Fivetran and BigQuery are easier to use and a stronger choice than what AWS offers for querying DynamoDB data with SQL. However, there are some downsides to this option, including:
- It's more expensive, mainly because of Fivetran -- BigQuery is priced comparably to Athena.
- When data moves from one cloud to another, Fivetran requires access to that data, and this could make compliance difficult or impossible, depending on your requirements.
- It has a built-in delay because there are coordinated, dependent steps that need to be completed to grab the necessary data. If you need to query the data more quickly, you could build your own custom solution based on DynamoDB streams and Amazon Kinesis, but these are all edge cases to the more general need to query DynamoDB with SQL.
AWS: Too big to fail?
The Fivetran and BigQuery option raises questions about AWS' ability to be best-in-breed. What should AWS do when it has an inferior service that still nominally does the job? The project teams are so siloed and distributed that it's highly unlikely AWS will build another service that competes directly with its existing tool. But it's also incredibly hard to see how AWS can improve Glue or Athena enough to be competitive.
The usability issues AWS has with Glue and Athena relate to the underlying open source projects that those services are based on -- Apache Spark and Presto, respectively. For example, the Spark analytics engine is highly configurable. It assumes users know how to code and will spend time learning the system. In contrast, Fivetran is opinionated and designed for simplicity, so users have to make as few decisions as possible.
This should raise some alarm bells within AWS. If it continues to ship open source software as managed services, AWS might struggle to win against products built as managed services from the ground up.
AWS started the revolution of delivering infrastructure as managed services, but it hasn't consistently built the best, most usable options with its higher-level offerings. This ultimately gives competitors room to capture customer revenue and steer those users to other infrastructure platforms.
Compute, storage and other infrastructure services remain AWS' bread and butter, but they're also the most fungible for users. For some enterprises, staying entirely within AWS may not be a good decision if their goal is to use the best services available, and that could create a much larger problem for AWS.






